Welcome to Knitting
Knitting is a shared-memory IPC library for Node.js, Deno, and Bun that makes worker-thread parallelism feel like normal function calls.
You’ve probably tried workers before and thought: this is way more wiring than it should be. That’s exactly why Knitting exists. It gives you multi-core JavaScript without the ceremony, so you can focus on what your code actually does instead of how it talks between threads.
This page walks you through the reasoning, the design, and the trade-offs. If you’d rather just start building, head straight to the Quick Start.
Why Knitting Exists
Section titled “Why Knitting Exists”JavaScript runs on a single thread. It handles I/O concurrency well, but when you need real CPU parallelism, you need Workers.
The thing is, most developers don’t use them. Not because parallelism isn’t useful, but because the ergonomics got in the way. When a server got hot, it was usually easier to scale out — spin up another process, another container, talk over HTTP — rather than deal with the worker boilerplate.
That works, but the cost adds up: more memory, more moving pieces, more latency, and a communication layer that has nothing to do with your actual logic.
Workers should be the answer. In practice, the workflow looks like this:
createa separate worker entry module,buildan event protocol on both sides,implementrouting and error handling,wrapeverything in promises,trackrequest IDs (and ordering, if FIFO matters),- then realize IPC overhead makes many small tasks
not worthoffloading.
None of that is hard. It’s just a lot of plumbing for something that should feel like calling a function.
The problem isn’t compute. The problem is the cost of reaching the compute.
With Knitting, that entire workflow collapses to about ten lines:
import { isMain, task } from "@vixeny/knitting";
export const world = task({ f: (args: string) => args + " world",}).createPool();
if (isMain) { world.call("hello") .then(console.log).finally(world.shutdown);}Three steps:
definetasks once,spin upa pool,callthem like functions.
The result is a worker workflow that stays out of your way and can run 4x to 200x faster than message-based IPC in communication-focused microbenchmarks for small-to-medium, high-frequency tasks. That reflects IPC overhead reduction, not an automatic end-to-end app speedup.
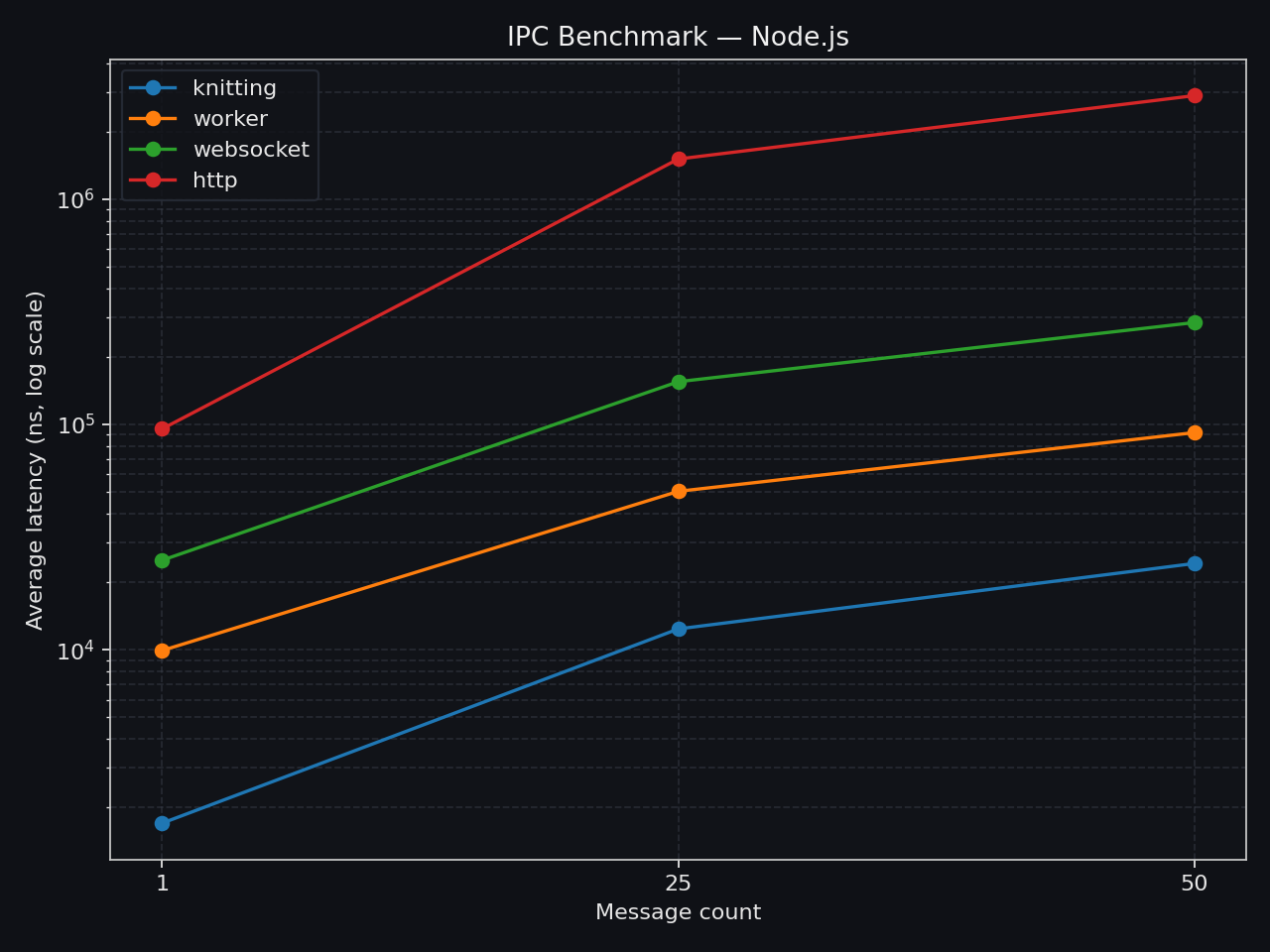
clk: ~3.67 GHzcpu: Apple M3 Ultraruntime: node 24.12.0 (arm64-darwin)
| • knitting | avg | min | p75 | p99 | max || --------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || 1 thread → (1) | ` 2.22 µs/iter` | ` 1.12 µs` | ` 2.63 µs` | ` 5.54 µs` | ` 1.27 ms` || 1 thread → (25) | ` 15.99 µs/iter` | ` 14.33 µs` | ` 16.56 µs` | ` 17.15 µs` | ` 19.87 µs` || 1 thread → (50) | ` 30.67 µs/iter` | ` 28.07 µs` | ` 31.19 µs` | ` 32.16 µs` | ` 33.21 µs` |clk: ~3.71 GHzcpu: Apple M3 Ultraruntime: node 24.12.0 (arm64-darwin)
| • websocket | avg | min | p75 | p99 | max || ------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || local → (1) | ` 26.83 µs/iter` | ` 12.83 µs` | ` 26.96 µs` | ` 85.25 µs` | `468.58 µs` || local → (25) | `183.39 µs/iter` | `130.33 µs` | `195.83 µs` | `272.71 µs` | `976.96 µs` || local → (50) | `345.79 µs/iter` | `252.42 µs` | `363.46 µs` | `456.25 µs` | ` 1.45 ms` |clk: ~3.70 GHzcpu: Apple M3 Ultraruntime: node 24.12.0 (arm64-darwin)
| • worker | avg | min | p75 | p99 | max || ------------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || postMessage → (1) | ` 11.49 µs/iter` | ` 7.29 µs` | ` 12.00 µs` | ` 33.21 µs` | `344.50 µs` || postMessage → (25) | ` 56.73 µs/iter` | ` 55.91 µs` | ` 56.83 µs` | ` 57.24 µs` | ` 57.76 µs` || postMessage → (50) | `102.10 µs/iter` | ` 68.83 µs` | `105.63 µs` | `221.17 µs` | ` 3.49 ms` |clk: ~3.68 GHzcpu: Apple M3 Ultraruntime: node 24.12.0 (arm64-darwin)
| • http | avg | min | p75 | p99 | max || ------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || local → (1) | ` 65.42 µs/iter` | ` 38.42 µs` | ` 66.13 µs` | `174.38 µs` | `601.33 µs` || local → (25) | `966.49 µs/iter` | `859.96 µs` | ` 1.01 ms` | ` 1.22 ms` | ` 2.04 ms` || local → (50) | ` 1.90 ms/iter` | ` 1.71 ms` | ` 1.99 ms` | ` 2.17 ms` | ` 2.64 ms` |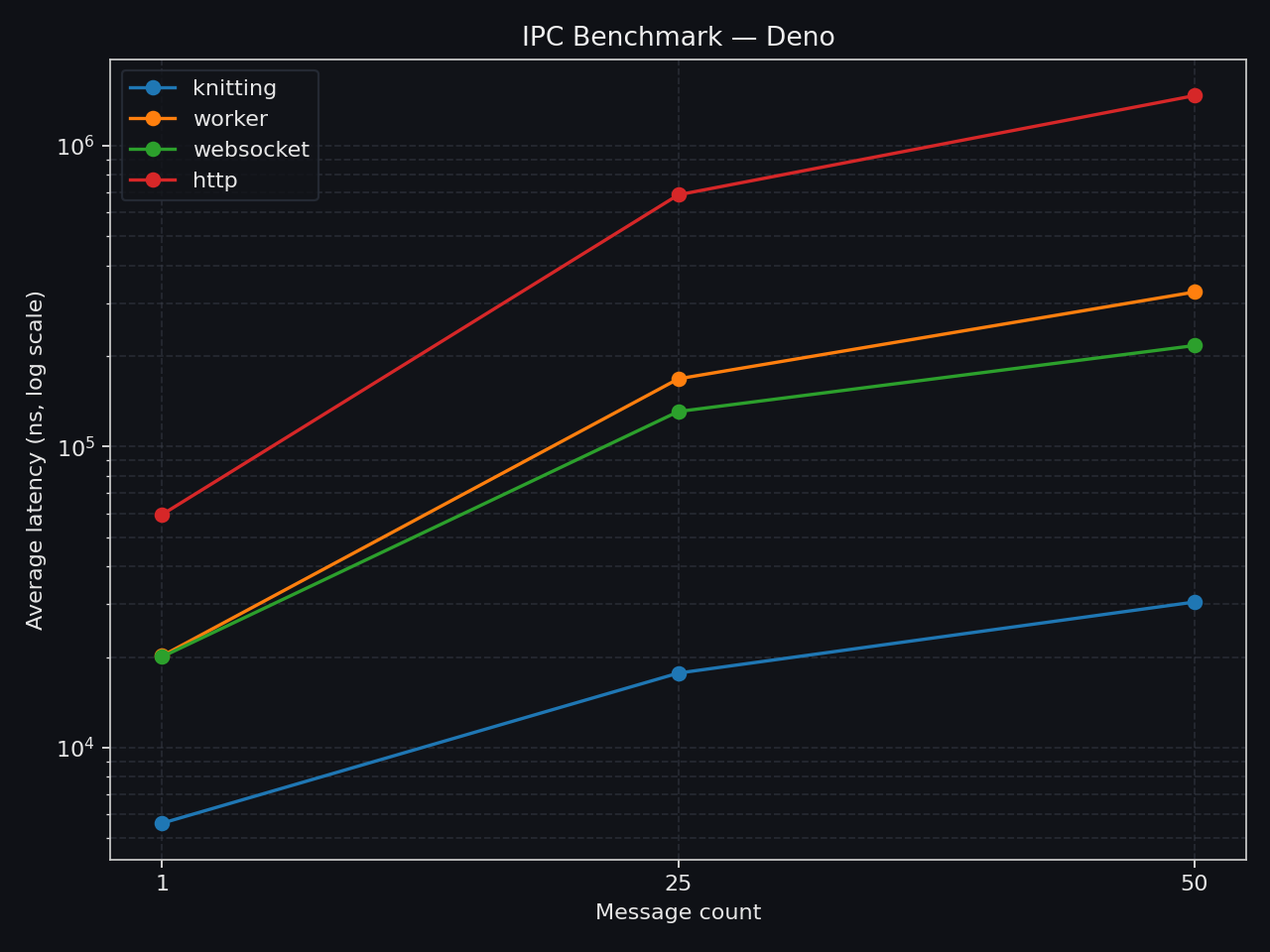
clk: ~3.60 GHzcpu: Apple M3 Ultraruntime: deno 2.6.6 (aarch64-apple-darwin)
| • knitting | avg | min | p75 | p99 | max || --------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || 1 thread → (1) | ` 6.24 µs/iter` | ` 1.17 µs` | ` 6.00 µs` | ` 25.21 µs` | `164.71 µs` || 1 thread → (25) | ` 14.86 µs/iter` | ` 13.43 µs` | ` 15.38 µs` | ` 15.41 µs` | ` 18.16 µs` || 1 thread → (50) | ` 28.20 µs/iter` | ` 25.98 µs` | ` 28.92 µs` | ` 29.64 µs` | ` 29.98 µs` |clk: ~3.60 GHzcpu: Apple M3 Ultraruntime: deno 2.6.6 (aarch64-apple-darwin)
| • websocket | avg | min | p75 | p99 | max || ------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || local → (1) | ` 24.92 µs/iter` | ` 14.00 µs` | ` 27.13 µs` | ` 83.38 µs` | `209.25 µs` || local → (25) | `142.08 µs/iter` | `109.33 µs` | `145.08 µs` | `252.46 µs` | `331.33 µs` || local → (50) | `228.86 µs/iter` | `189.08 µs` | `238.92 µs` | `354.13 µs` | `466.83 µs` |clk: ~3.60 GHzcpu: Apple M3 Ultraruntime: deno 2.6.6 (aarch64-apple-darwin)
| • worker | avg | min | p75 | p99 | max || ------------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || postMessage → (1) | ` 22.93 µs/iter` | ` 14.63 µs` | ` 23.54 µs` | ` 67.33 µs` | `229.79 µs` || postMessage → (25) | `181.86 µs/iter` | `137.13 µs` | `191.71 µs` | `311.67 µs` | ` 1.88 ms` || postMessage → (50) | `353.30 µs/iter` | `280.42 µs` | `373.38 µs` | `544.17 µs` | ` 2.04 ms` |clk: ~3.61 GHzcpu: Apple M3 Ultraruntime: deno 2.6.6 (aarch64-apple-darwin)
| • http | avg | min | p75 | p99 | max || ------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || local → (1) | ` 65.63 µs/iter` | ` 40.63 µs` | ` 65.92 µs` | `165.63 µs` | ` 1.08 ms` || local → (25) | `810.26 µs/iter` | `654.79 µs` | `839.88 µs` | ` 1.77 ms` | ` 1.93 ms` || local → (50) | ` 1.62 ms/iter` | ` 1.29 ms` | ` 1.73 ms` | ` 2.61 ms` | ` 2.72 ms` |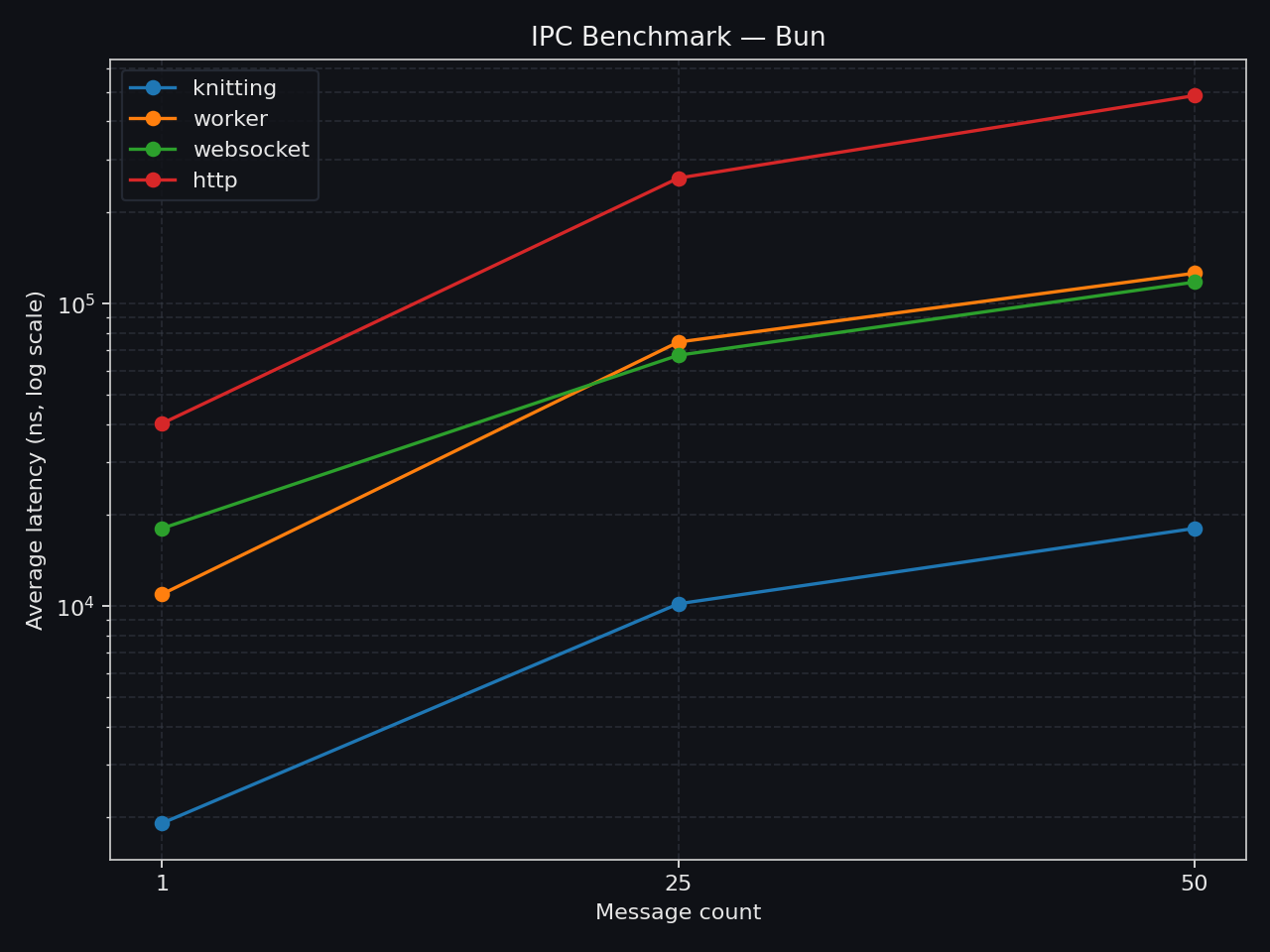
clk: ~3.70 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • knitting | avg | min | p75 | p99 | max || --------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || 1 thread → (1) | ` 2.68 µs/iter` | ` 1.97 µs` | ` 2.91 µs` | ` 3.42 µs` | ` 3.55 µs` || 1 thread → (25) | ` 14.62 µs/iter` | ` 12.43 µs` | ` 15.19 µs` | ` 15.97 µs` | ` 16.67 µs` || 1 thread → (50) | ` 26.43 µs/iter` | ` 23.69 µs` | ` 27.47 µs` | ` 28.26 µs` | ` 28.71 µs` |clk: ~3.70 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • websocket | avg | min | p75 | p99 | max || ------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || local → (1) | ` 21.65 µs/iter` | ` 8.04 µs` | ` 21.33 µs` | ` 69.00 µs` | `312.63 µs` || local → (25) | ` 73.20 µs/iter` | ` 52.08 µs` | ` 75.04 µs` | `183.00 µs` | `459.58 µs` || local → (50) | `128.42 µs/iter` | ` 91.71 µs` | `132.17 µs` | `275.25 µs` | `543.67 µs` |clk: ~3.70 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • worker | avg | min | p75 | p99 | max || ------------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || postMessage → (1) | ` 11.68 µs/iter` | ` 7.38 µs` | ` 11.75 µs` | ` 37.75 µs` | `433.88 µs` || postMessage → (25) | ` 79.84 µs/iter` | ` 47.92 µs` | ` 79.54 µs` | `342.04 µs` | ` 1.20 ms` || postMessage → (50) | `139.38 µs/iter` | ` 91.58 µs` | `147.17 µs` | `516.08 µs` | ` 1.16 ms` |clk: ~3.66 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • http | avg | min | p75 | p99 | max || ------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || local → (1) | ` 44.32 µs/iter` | ` 29.67 µs` | ` 43.79 µs` | `121.21 µs` | `355.92 µs` || local → (25) | `343.94 µs/iter` | `243.54 µs` | `393.46 µs` | `580.08 µs` | `717.88 µs` || local → (50) | `724.11 µs/iter` | `492.92 µs` | `792.42 µs` | ` 1.03 ms` | ` 1.13 ms` |What Knitting Is
Section titled “What Knitting Is”At its simplest: a shared-memory IPC transport for JavaScript runtimes that keeps things simple.
For the technically curious:
Knitting is a full-duplex shared-memory IPC transport built from two independent 32-slot shared mailboxes (request and response), using bitset slot ownership and futex-style wakeups with optional spin-pause.
The design rests on a few deliberate choices.
Core Design Principles
Section titled “Core Design Principles”Tasks, not messages You export functions. The pool executes them. No message protocols, no custom serialization layers between you and the work.
Explicit configuration Routing strategy, batching limits, stall backoff, timeouts, and inline execution are choices you make, not hidden defaults.
Efficient idle behavior Workers spin briefly when needed, trigger a garbage collection if no work arrives (so the idle time is productive, not wasted), then park and wake only when there’s actual work. No CPU burn while waiting.
The Worker Runtime
Section titled “The Worker Runtime”Each worker is a real OS thread spawned through the runtime’s native worker API (worker_threads on Node, Worker on Deno and Bun). When a pool starts, every worker goes through the same lifecycle:
- Boot — the worker process starts and imports your task modules from the URL list passed at spawn time. Each exported task becomes an entry in an internal function table, indexed by task ID.
- Signal ready — the worker writes a status flag into shared memory so the host knows this lane is available.
- Enter the main loop — a tight cycle that runs three phases per iteration:
- Enqueue — read new request slots from the shared request mailbox.
- Service — execute pending tasks (sync or async) in batches of up to 32.
- Write-back — flush completed results into the response mailbox so the host can resolve promises.
- Sleep when idle — when there’s nothing to do, the worker spins briefly (configurable via
spinMicroseconds). If no work arrives during the spin window, it triggers a garbage collection (global.gc()) — using idle time productively instead of just spinning. Then it parks usingAtomics.wait(a futex-style block). It stays parked — zero CPU — until the host writes new work and wakes it withAtomics.notify.
Async tasks (functions returning a promise) are fully awaited inside the worker before the result is written back. There are no half-resolved values crossing the thread boundary.
This loop is the same on all three runtimes. The only runtime-specific part is how the worker thread is created — after that, everything runs through shared memory.
Why It’s Fast (and When That Matters)
Section titled “Why It’s Fast (and When That Matters)”The performance gains aren’t magic — they come from removing the overhead that makes workers impractical for small tasks:
- Low IPC overhead: shared-memory mailboxes skip serialization and message hops entirely.
- Batch-friendly execution: work is encoded, dispatched, and resolved through a pipelined flow.
- GC when idle, sleep when quiet: workers run garbage collection during idle spin windows (so idle time is productive), then park and wake only when there’s work.
- Event-loop friendly: everything cooperates with the event loop. No blocking, no forced
await, just predictable behavior. - Pressure-responsive: higher load improves throughput instead of stalling.
This matters most when the coordination cost would otherwise dominate the actual computation.
Knitting doesn’t make slow code fast. It makes parallel code cheap enough to be worth writing.
What Knitting Is Good For
Section titled “What Knitting Is Good For”Knitting is built for workloads where CPU pressure comes in bursts and you need the main thread to stay responsive:
- Math and simulation: Big prime, Monte Carlo, Physics loop, TSP (GSA).
- Data transforms: Overview, Schema validation, JWT revalidation, Salt hashing, Prompt token budgeting, React SSR, React SSR + compression, Hono server, Markdown to HTML.
- Web servers under load: offload expensive requests so cheap routes keep flowing.
- High-frequency background jobs: many small tasks where batching and low overhead compound.
Design Boundaries
Section titled “Design Boundaries”It solves one problem well and doesn’t try to be everything. Being upfront about that saves everyone time.
**Not a replacement for postMessage: **
postMessage is great for general-purpose messaging. Knitting occupies a different niche: structured task execution with minimal overhead. Use whichever fits your workload, or both.
No edge runtimes yet Node.js, Deno, and Bun are the current targets. Edge runtimes have different isolation models, limited shared memory, and different module lifecycles. Supporting them properly would require careful design, not a quick port.
Remote imports (with caution) Knitting can load task modules from remote sources, but doing so widens your trust boundary. Because of security and supply-chain concerns, remote import support may be restricted or removed in future releases.
Not a distributed system Knitting operates within a single process, across threads, using shared memory. If you need cross-machine distribution, Knitting is meant to complement that layer, not replace it.