This page is the high-level benchmark summary across Node, Deno, and Bun, with a Tokio close-up for the small-payload fast path.
For runtime-specific detail, see the dedicated pages for Node, Deno, Bun, and Tokio.
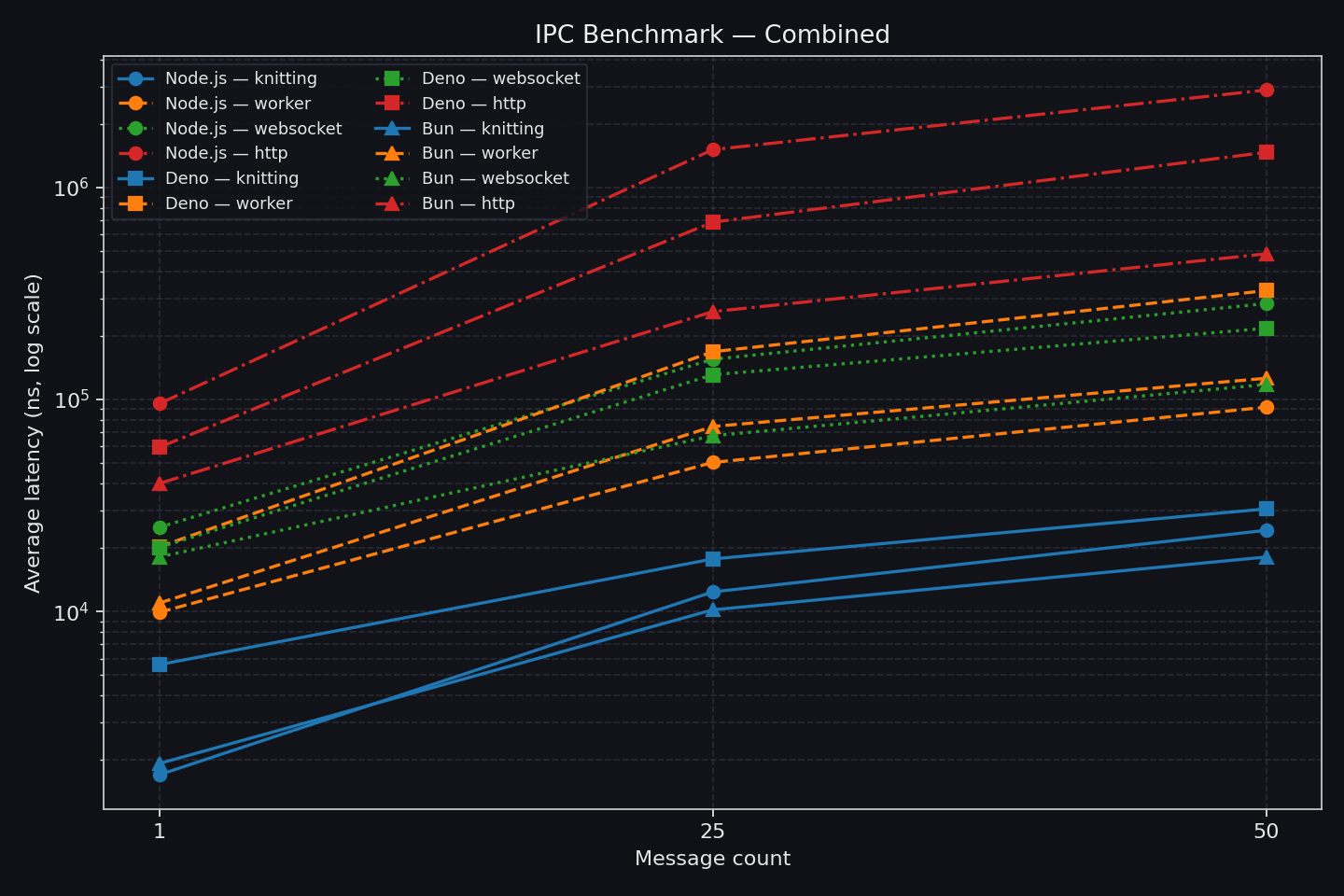
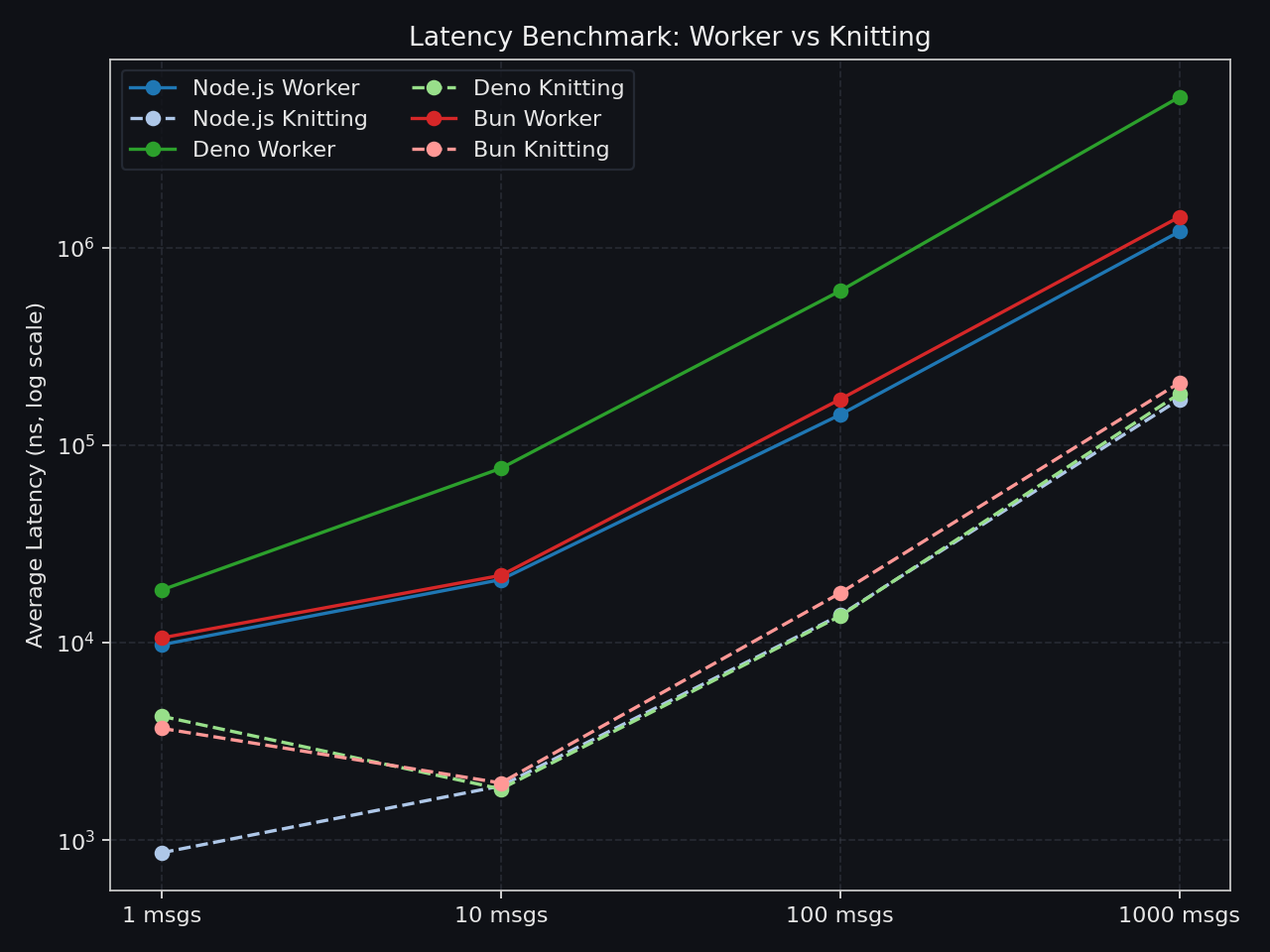
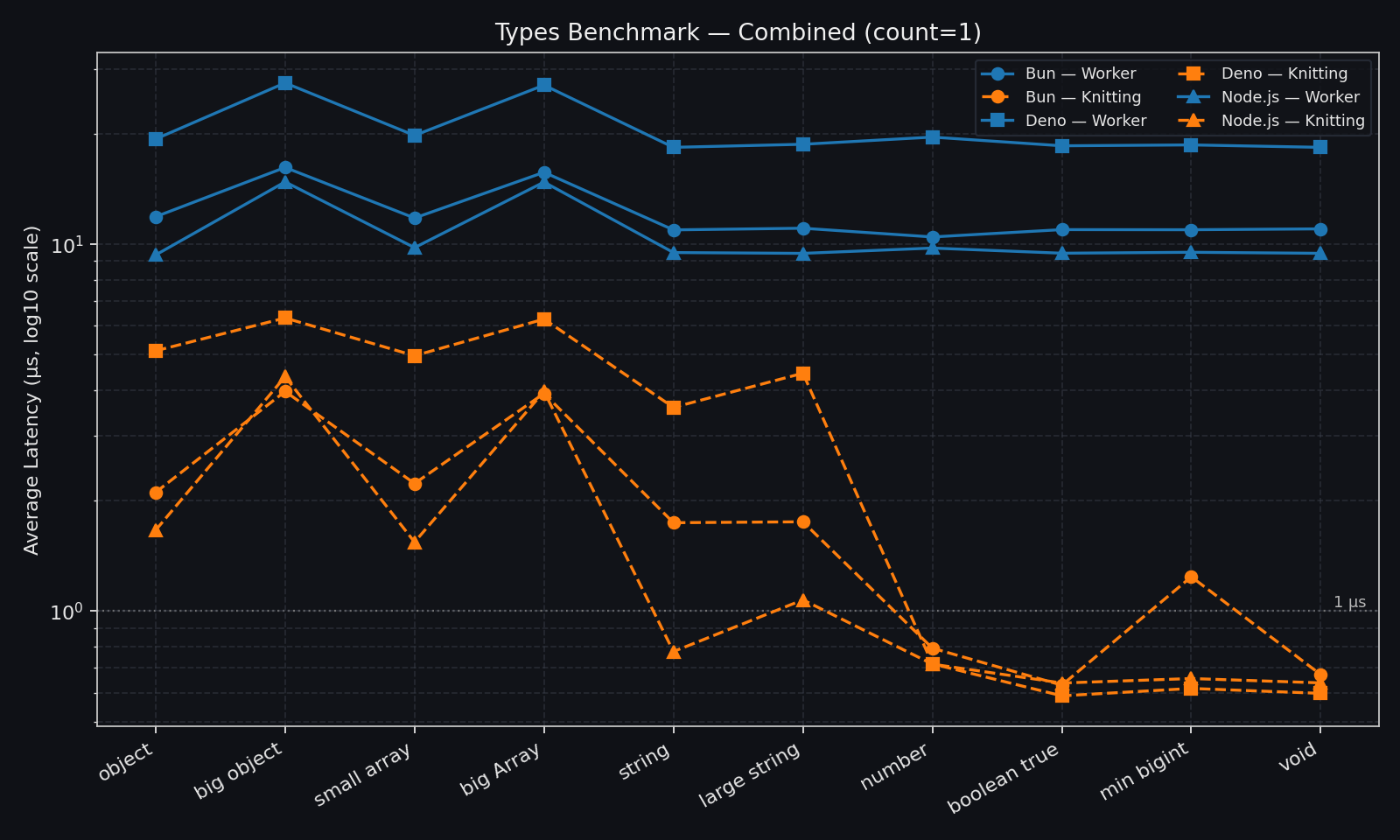
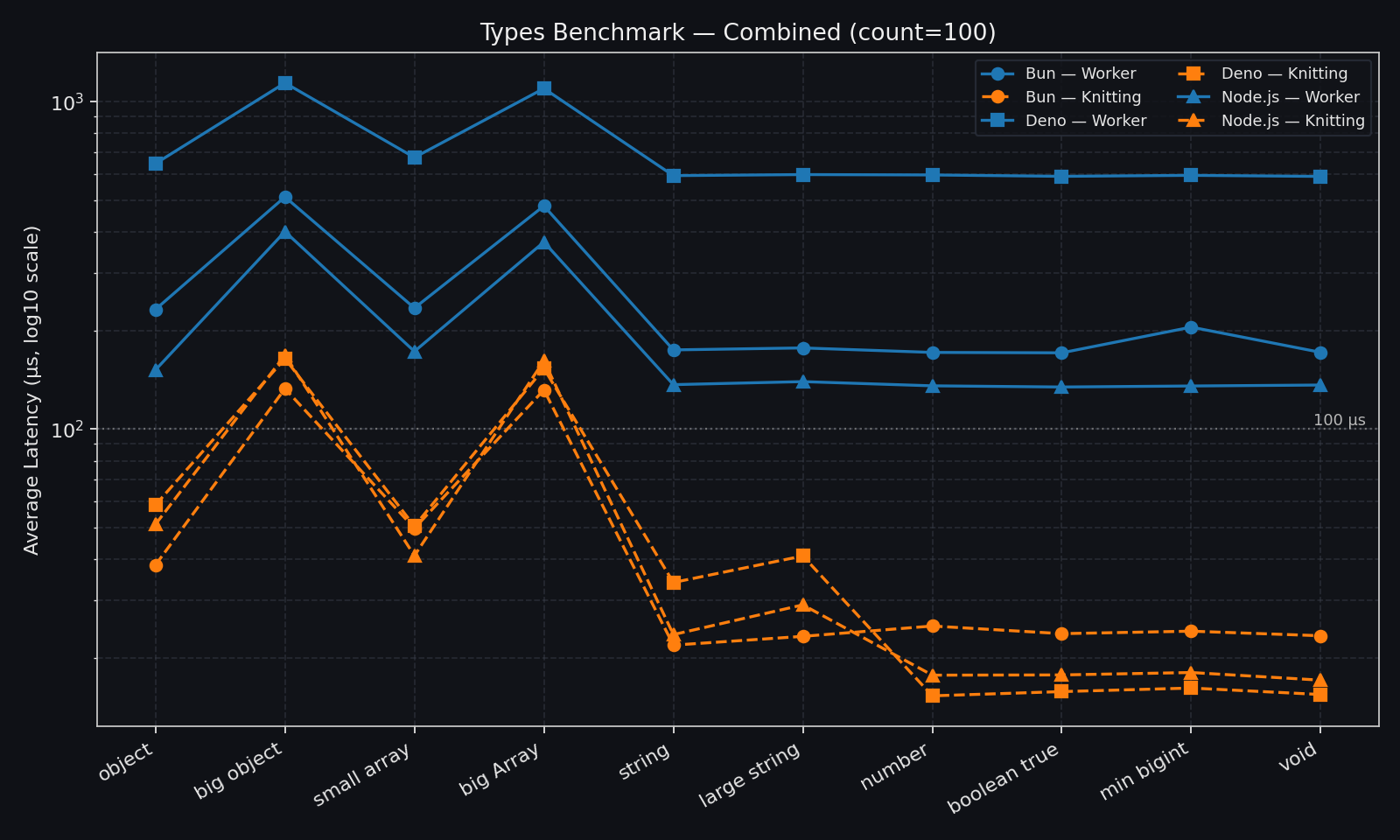
These benchmarks quantify communication overhead and scaling behavior in specific benchmark shapes.
They are not a direct prediction of end-to-end application speedup.
End-to-end message latency as batch size increases
Payload sensitivity (primitive, structured, and binary types)
Throughput at growing payload sizes (up to 1 MiB)
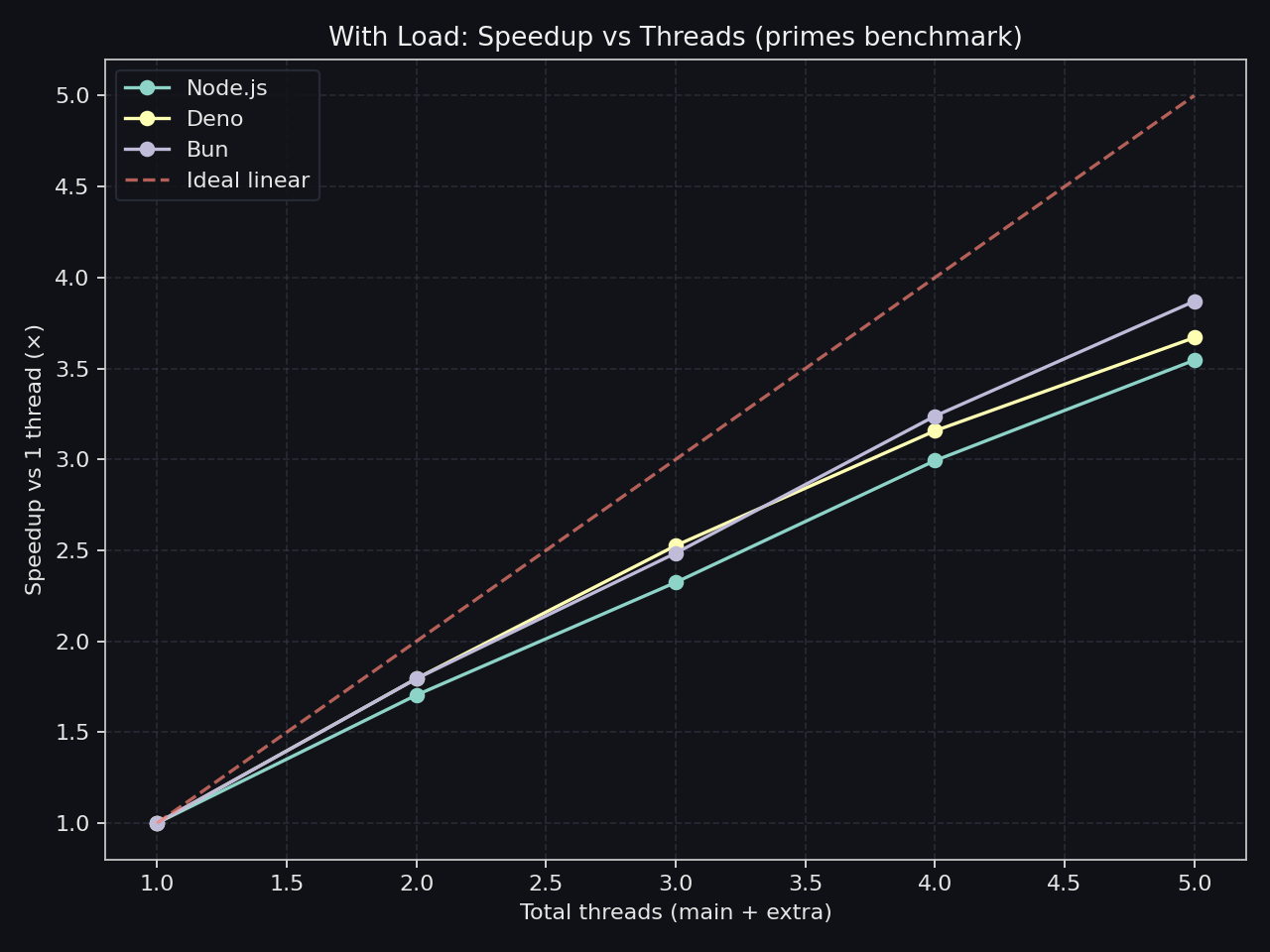
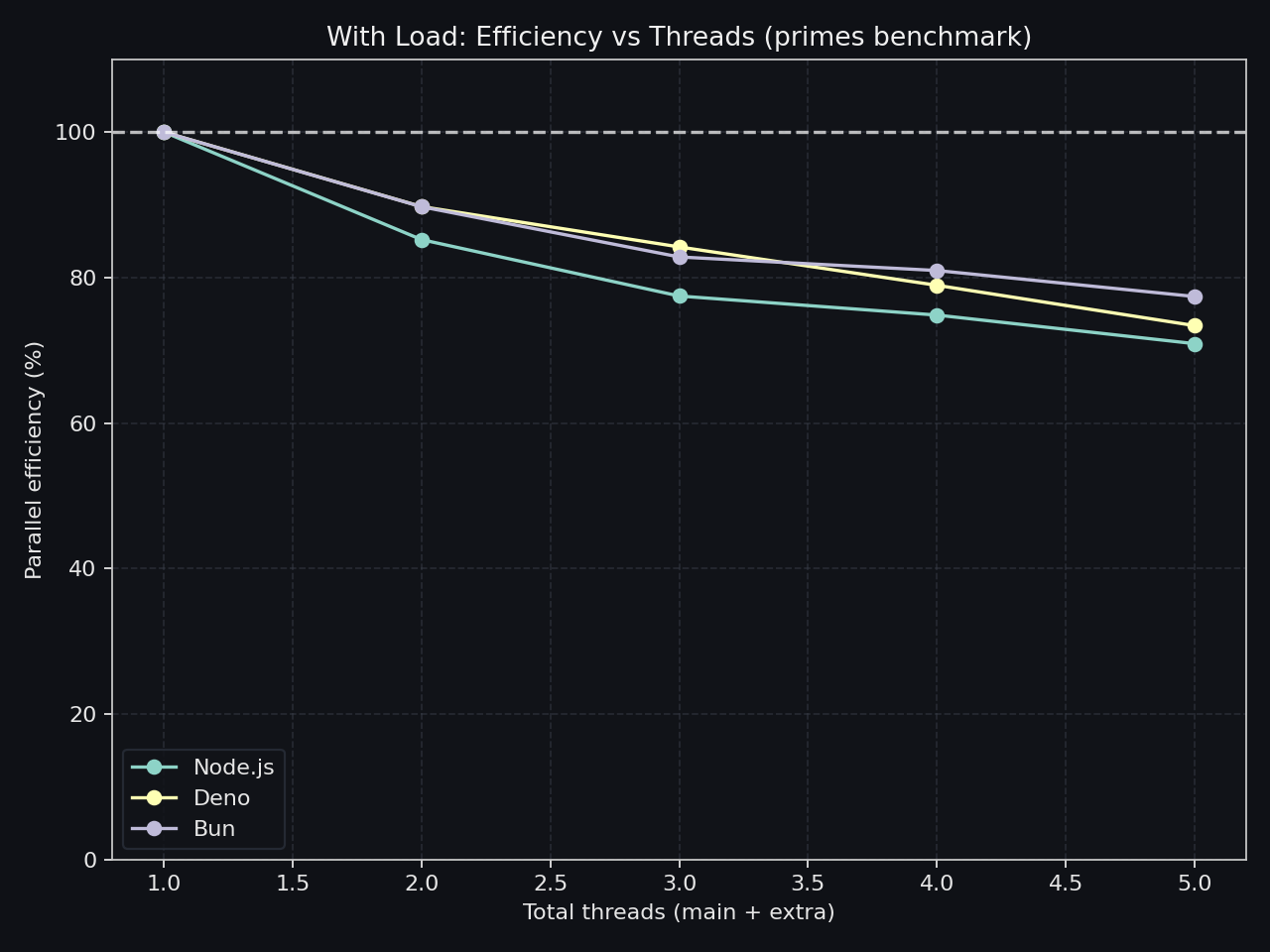
Heavy-task scaling and parallel efficiency under CPU-intensive workloads
Interpretation rule: “x faster” here means faster for this benchmark setup (payloads, batching, CPU profile), not universally x faster for any app.
Tokio close-up
Primitive handoffs, copy-heavy bytes, and a separate Arc reference
This close-up mixes two kinds of communication cost: primitive handoff slices and one
copy-heavy Uint8Array slice from the fairer default tables. The
Arc<Vec<u8>> card is separate and should be read as a Tokio shared-ownership
reference, not as the default apples-to-apples byte comparison. Markers to the left are
faster, markers to the right are slower.
Highlighted cases: f64, copied Uint8Array, Arc referenceScope: communication cost, not end-to-end throughputMetric: average latency, lower is better
number f64 · batch 1
Primitive handoff only: Node and Bun are faster, Tokio stays ahead of Deno, and all four remain in the 6-22 µs range.
0.5x1.0x Tokio1.8x
T
B
N
D
Tokio13.01 µsbaseline
Bun + Knitting7.35 µs44% faster
Node + Knitting6.63 µs49% faster
Deno + Knitting21.54 µs66% slower
number f64 · batch 10
Still a handoff-cost slice: Bun, Node, and Deno stay below 20 µs, while Tokio averages 27.50 µs.
0.5x1.0x Tokio1.8x
T
B
N
D
Tokio27.50 µsbaseline
Bun + Knitting13.41 µs51% faster
Node + Knitting17.28 µs37% faster
Deno + Knitting11.97 µs56% faster
Uint8Array 512 KiB · batch 100
This is the copy/clone-heavy byte path: Bun and Node edge Tokio on average, while Deno is a bit slower and all four land in the same 22-25 ms band.
0.5x1.0x Tokio1.8x
T
B
N
D
Tokio23.06 msbaseline
Bun + Knitting22.33 ms3% faster
Node + Knitting22.66 ms2% faster
Deno + Knitting25.26 ms10% slower
Arc<Vec<u8>> ref · 512 B · batch 100
Separate Tokio shared-ownership reference, not the default byte benchmark: Bun stays within 6% of Tokio, while Node and Deno are slower.
0.5x1.0x Tokio1.8x
T
B
N
D
Tokio79.51 µsbaseline
Bun + Knitting74.78 µs6% faster
Node + Knitting97.23 µs22% slower
Deno + Knitting123.11 µs55% slower
Primitive and copied-byte rows come from the fairer default comparison. The Arc row is
included as a separate small-payload shared-ownership reference.
For primitive calls and low binary payloads, Knitting stays in the same microsecond tier as Tokio in these benchmark shapes.
Read that as handoff cost: wakeups/signaling plus copying or cloning very small payloads, not a claim that every payload shape matches Tokio.
That matters because it shows the shared-memory fast path is not just “good for JavaScript” — it can stay competitive with a Rust baseline when coordination dominates.