Bun
This page summarizes Bun benchmark runs for Knitting on bun 1.3.6 (arm64-darwin).
IPC (Bun)
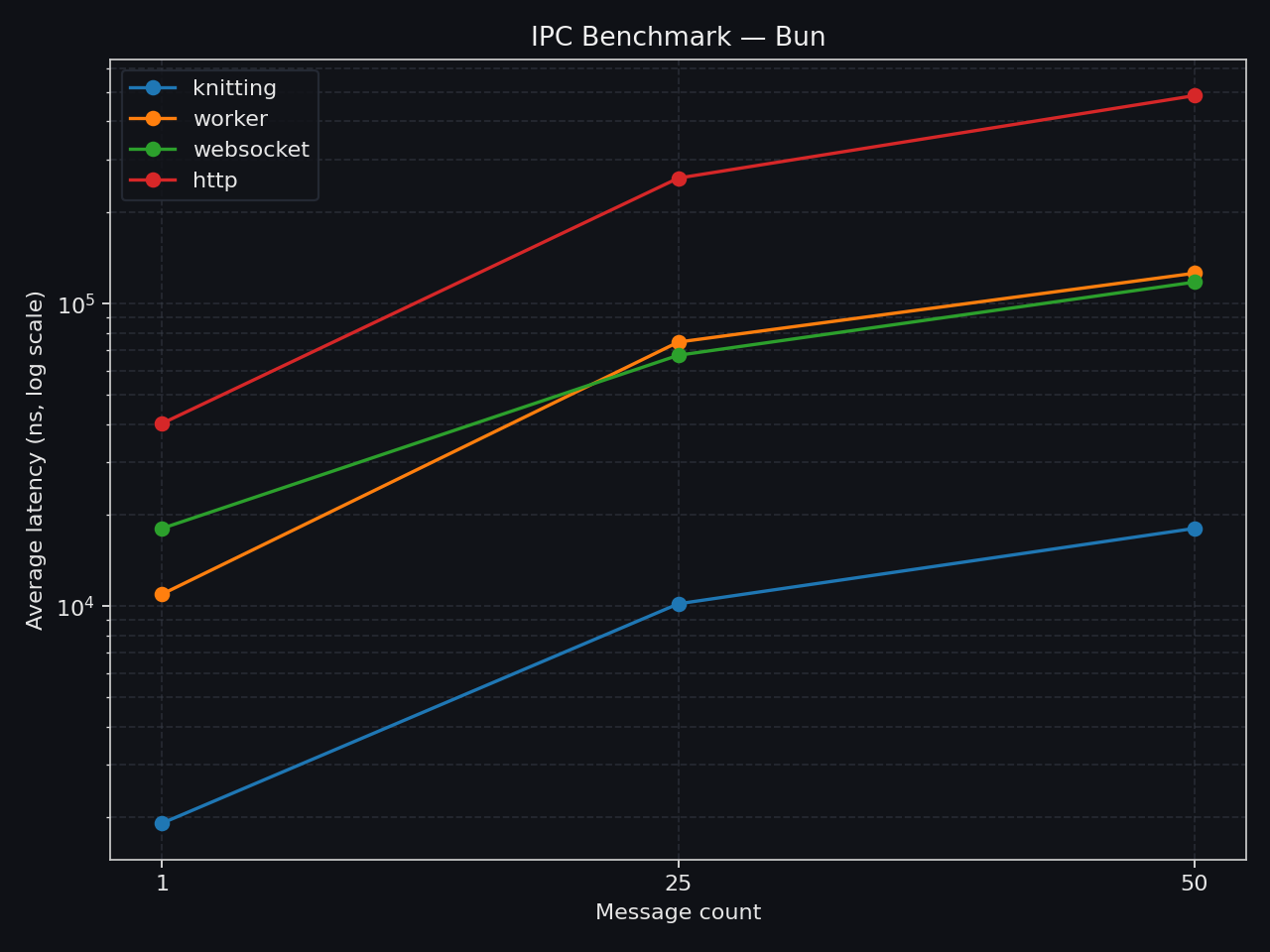
Section titled “IPC (Bun)”This benchmark compares one round-trip between a main thread and workers using different transports. Knitting keeps the lowest overhead in this setup:
1message: Knitting is about5.7xfaster than workerpostMessage,9.5xfaster than websocket, and21xfaster than HTTP.25messages: Knitting is about7.4xfaster than workerpostMessage.50messages: Knitting is about7xfaster than workerpostMessage.
clk: ~3.70 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • knitting | avg | min | p75 | p99 | max || --------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || 1 thread → (1) | ` 2.68 µs/iter` | ` 1.97 µs` | ` 2.91 µs` | ` 3.42 µs` | ` 3.55 µs` || 1 thread → (25) | ` 14.62 µs/iter` | ` 12.43 µs` | ` 15.19 µs` | ` 15.97 µs` | ` 16.67 µs` || 1 thread → (50) | ` 26.43 µs/iter` | ` 23.69 µs` | ` 27.47 µs` | ` 28.26 µs` | ` 28.71 µs` |clk: ~3.70 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • websocket | avg | min | p75 | p99 | max || ------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || local → (1) | ` 21.65 µs/iter` | ` 8.04 µs` | ` 21.33 µs` | ` 69.00 µs` | `312.63 µs` || local → (25) | ` 73.20 µs/iter` | ` 52.08 µs` | ` 75.04 µs` | `183.00 µs` | `459.58 µs` || local → (50) | `128.42 µs/iter` | ` 91.71 µs` | `132.17 µs` | `275.25 µs` | `543.67 µs` |clk: ~3.70 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • worker | avg | min | p75 | p99 | max || ------------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || postMessage → (1) | ` 11.68 µs/iter` | ` 7.38 µs` | ` 11.75 µs` | ` 37.75 µs` | `433.88 µs` || postMessage → (25) | ` 79.84 µs/iter` | ` 47.92 µs` | ` 79.54 µs` | `342.04 µs` | ` 1.20 ms` || postMessage → (50) | `139.38 µs/iter` | ` 91.58 µs` | `147.17 µs` | `516.08 µs` | ` 1.16 ms` |clk: ~3.66 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • http | avg | min | p75 | p99 | max || ------------ | ---------------- | ----------- | ----------- | ----------- | ----------- || local → (1) | ` 44.32 µs/iter` | ` 29.67 µs` | ` 43.79 µs` | `121.21 µs` | `355.92 µs` || local → (25) | `343.94 µs/iter` | `243.54 µs` | `393.46 µs` | `580.08 µs` | `717.88 µs` || local → (50) | `724.11 µs/iter` | `492.92 µs` | `792.42 µs` | ` 1.03 ms` | ` 1.13 ms` |Knitting vs Worker (Bun)
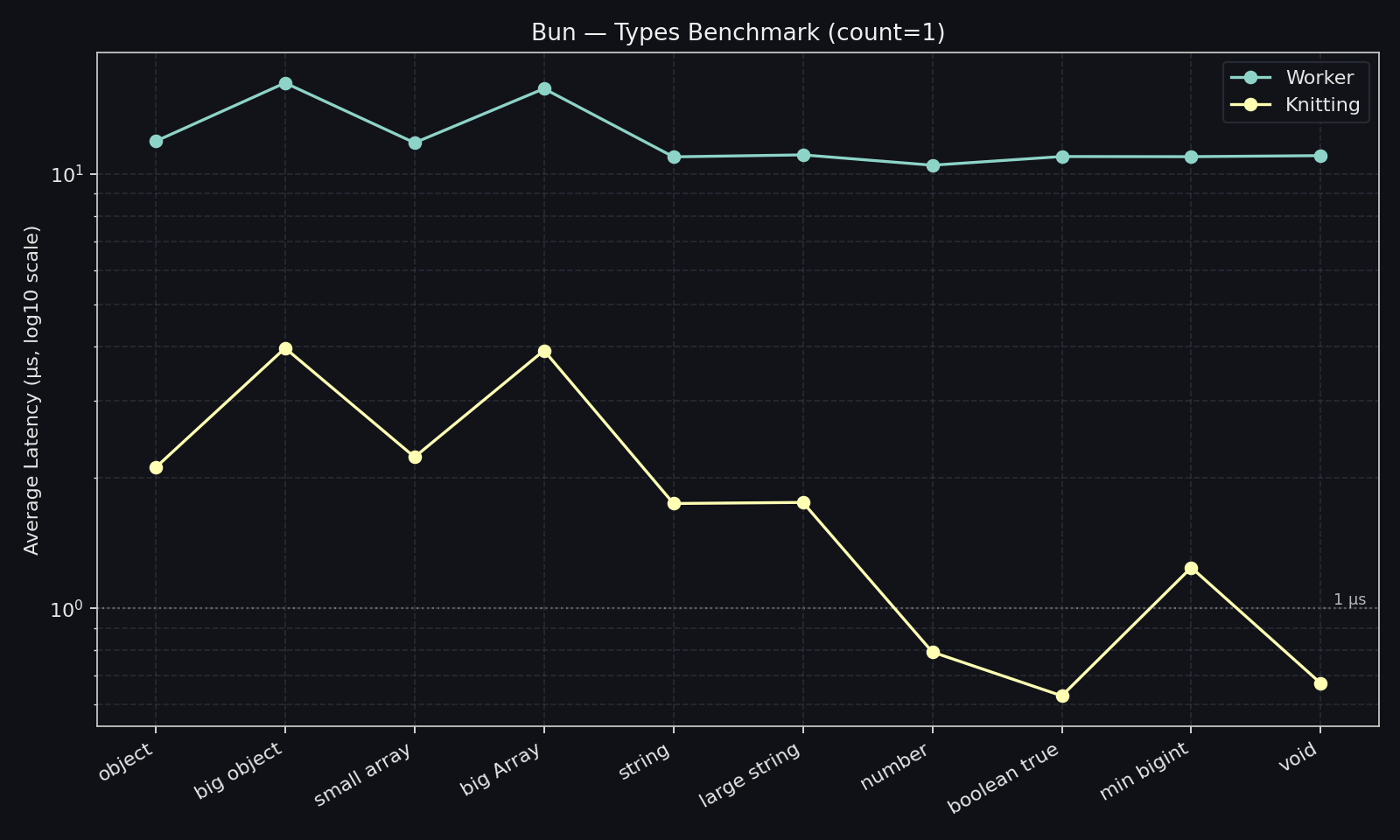
Section titled “Knitting vs Worker (Bun)”These charts compare the same payload families sent through Knitting and Bun workers.
One message
Section titled “One message”With a single value per call, Knitting is consistently faster:
- For small primitives, Knitting is roughly
~6-17xfaster than workers. - For string/array/object payloads, Knitting is usually around
~4-6xfaster. - For larger payloads, Knitting still holds a clear advantage (for example, big object:
3.97 µsvs16.38 µs, about4.1xfaster).
clk: ~3.67 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • knitting 1 | avg | min | p75 | p99 | max || --------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (1) | ` 2.13 µs/iter` | `500.00 ns` | ` 2.96 µs` | ` 8.71 µs` | `362.42 µs` || bigint small -> (1) | ` 2.14 µs/iter` | ` 1.35 µs` | ` 2.49 µs` | ` 3.15 µs` | ` 3.18 µs` || bigint large -> (1) | ` 4.10 µs/iter` | ` 2.08 µs` | ` 4.13 µs` | ` 11.83 µs` | ` 1.64 ms` || boolean true -> (1) | ` 1.26 µs/iter` | `609.65 ns` | ` 1.78 µs` | ` 2.82 µs` | ` 2.86 µs` || boolean false -> (1) | ` 1.35 µs/iter` | `628.39 ns` | ` 1.85 µs` | ` 2.93 µs` | ` 2.95 µs` || undefined -> (1) | ` 1.40 µs/iter` | `621.26 ns` | ` 1.93 µs` | ` 2.69 µs` | ` 2.77 µs` || null -> (1) | ` 1.44 µs/iter` | `634.12 ns` | ` 1.97 µs` | ` 2.71 µs` | ` 2.97 µs` || string -> (1) | ` 2.75 µs/iter` | `625.00 ns` | ` 3.21 µs` | ` 8.79 µs` | `384.17 µs` || json object -> (1) | ` 4.50 µs/iter` | ` 2.33 µs` | ` 5.00 µs` | ` 16.29 µs` | ` 1.48 ms` || json array -> (1) | ` 4.79 µs/iter` | ` 4.23 µs` | ` 4.92 µs` | ` 5.31 µs` | ` 5.31 µs` || Uint8Array -> (1) | ` 4.17 µs/iter` | ` 1.58 µs` | ` 4.38 µs` | ` 12.25 µs` | ` 3.37 ms` || ArrayBuffer -> (1) | ` 4.37 µs/iter` | ` 1.38 µs` | ` 4.79 µs` | ` 12.42 µs` | ` 3.04 ms` || Buffer -> (1) | ` 3.57 µs/iter` | ` 2.61 µs` | ` 3.85 µs` | ` 4.43 µs` | ` 4.46 µs` || string huge -> (1) | ` 3.52 µs/iter` | ` 2.57 µs` | ` 3.86 µs` | ` 4.07 µs` | ` 4.25 µs` || Int32Array -> (1) | ` 3.81 µs/iter` | ` 2.85 µs` | ` 4.16 µs` | ` 4.82 µs` | ` 4.94 µs` || Float64Array -> (1) | ` 3.50 µs/iter` | ` 1.13 µs` | ` 3.75 µs` | ` 10.75 µs` | ` 1.51 ms` || BigInt64Array -> (1) | ` 4.03 µs/iter` | ` 2.80 µs` | ` 4.52 µs` | ` 4.94 µs` | ` 5.04 µs` || BigUint64Array -> (1) | ` 4.04 µs/iter` | ` 2.79 µs` | ` 4.58 µs` | ` 5.14 µs` | ` 5.19 µs` || DataView -> (1) | ` 4.02 µs/iter` | ` 2.93 µs` | ` 4.40 µs` | ` 5.01 µs` | ` 5.04 µs` || Date -> (1) | ` 2.29 µs/iter` | ` 1.25 µs` | ` 2.71 µs` | ` 3.08 µs` | ` 3.11 µs` |
| • knitting 100 | avg | min | p75 | p99 | max || ----------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (100) | ` 31.40 µs/iter` | ` 14.96 µs` | ` 41.63 µs` | ` 86.79 µs` | ` 4.11 ms` || bigint small -> (100) | ` 32.56 µs/iter` | ` 29.93 µs` | ` 34.02 µs` | ` 34.18 µs` | ` 34.25 µs` || bigint large -> (100) | `116.20 µs/iter` | ` 82.33 µs` | `114.04 µs` | `366.38 µs` | ` 1.67 ms` || boolean true -> (100) | ` 31.78 µs/iter` | ` 24.84 µs` | ` 33.50 µs` | ` 34.93 µs` | ` 35.44 µs` || boolean false -> (100) | ` 31.52 µs/iter` | ` 27.25 µs` | ` 32.22 µs` | ` 35.46 µs` | ` 36.06 µs` || undefined -> (100) | ` 32.86 µs/iter` | ` 27.91 µs` | ` 34.44 µs` | ` 35.93 µs` | ` 38.27 µs` || null -> (100) | ` 32.75 µs/iter` | ` 27.48 µs` | ` 35.88 µs` | ` 37.04 µs` | ` 37.32 µs` || string -> (100) | ` 34.33 µs/iter` | ` 29.95 µs` | ` 36.04 µs` | ` 37.41 µs` | ` 39.64 µs` || json object -> (100) | `121.78 µs/iter` | ` 89.04 µs` | `125.21 µs` | `221.00 µs` | `544.79 µs` || json array -> (100) | `146.27 µs/iter` | `114.50 µs` | `151.71 µs` | `263.79 µs` | ` 1.62 ms` || Uint8Array -> (100) | `113.40 µs/iter` | ` 53.58 µs` | `113.33 µs` | `947.38 µs` | ` 3.12 ms` || ArrayBuffer -> (100) | `108.31 µs/iter` | ` 47.63 µs` | `108.71 µs` | `924.00 µs` | ` 3.18 ms` || Buffer -> (100) | `106.11 µs/iter` | ` 45.54 µs` | `114.92 µs` | `879.42 µs` | ` 1.79 ms` || string huge -> (100) | ` 79.03 µs/iter` | ` 38.88 µs` | ` 92.92 µs` | `191.17 µs` | ` 1.68 ms` || Int32Array -> (100) | `103.97 µs/iter` | ` 49.96 µs` | ` 98.42 µs` | `949.13 µs` | ` 3.45 ms` || Float64Array -> (100) | ` 70.94 µs/iter` | ` 37.46 µs` | ` 81.75 µs` | `158.42 µs` | ` 1.69 ms` || BigInt64Array -> (100) | `106.06 µs/iter` | ` 49.83 µs` | ` 99.50 µs` | `981.92 µs` | ` 3.84 ms` || BigUint64Array -> (100) | `104.32 µs/iter` | ` 50.96 µs` | ` 99.50 µs` | `946.75 µs` | ` 4.07 ms` || DataView -> (100) | `100.39 µs/iter` | ` 51.21 µs` | ` 98.75 µs` | `933.13 µs` | ` 3.82 ms` || Date -> (100) | ` 31.76 µs/iter` | ` 26.90 µs` | ` 33.15 µs` | ` 33.81 µs` | ` 37.27 µs` |
| • worker 1 | avg | min | p75 | p99 | max || --------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (1) | ` 11.23 µs/iter` | ` 6.08 µs` | ` 11.42 µs` | ` 37.38 µs` | `397.63 µs` || bigint small -> (1) | ` 11.48 µs/iter` | ` 11.35 µs` | ` 11.52 µs` | ` 11.57 µs` | ` 11.61 µs` || bigint large -> (1) | ` 11.42 µs/iter` | ` 11.29 µs` | ` 11.47 µs` | ` 11.47 µs` | ` 11.48 µs` || boolean true -> (1) | ` 11.58 µs/iter` | ` 11.53 µs` | ` 11.60 µs` | ` 11.61 µs` | ` 11.67 µs` || boolean false -> (1) | ` 11.53 µs/iter` | ` 11.49 µs` | ` 11.54 µs` | ` 11.57 µs` | ` 11.58 µs` || undefined -> (1) | ` 11.52 µs/iter` | ` 11.47 µs` | ` 11.54 µs` | ` 11.56 µs` | ` 11.60 µs` || null -> (1) | ` 11.57 µs/iter` | ` 11.47 µs` | ` 11.60 µs` | ` 11.63 µs` | ` 11.64 µs` || string -> (1) | ` 11.62 µs/iter` | ` 11.53 µs` | ` 11.65 µs` | ` 11.68 µs` | ` 11.69 µs` || json object -> (1) | ` 15.02 µs/iter` | ` 14.88 µs` | ` 15.07 µs` | ` 15.19 µs` | ` 15.27 µs` || json array -> (1) | ` 17.80 µs/iter` | ` 17.65 µs` | ` 17.92 µs` | ` 17.95 µs` | ` 18.00 µs` || Uint8Array -> (1) | ` 12.96 µs/iter` | ` 12.84 µs` | ` 13.00 µs` | ` 13.04 µs` | ` 13.06 µs` || ArrayBuffer -> (1) | ` 12.41 µs/iter` | ` 12.31 µs` | ` 12.45 µs` | ` 12.51 µs` | ` 12.63 µs` || Buffer -> (1) | ` 12.94 µs/iter` | ` 12.86 µs` | ` 12.99 µs` | ` 13.01 µs` | ` 13.07 µs` || string huge -> (1) | ` 11.68 µs/iter` | ` 11.57 µs` | ` 11.69 µs` | ` 11.73 µs` | ` 11.76 µs` || Int32Array -> (1) | ` 12.99 µs/iter` | ` 12.85 µs` | ` 13.04 µs` | ` 13.07 µs` | ` 13.08 µs` || Float64Array -> (1) | ` 12.97 µs/iter` | ` 12.81 µs` | ` 12.98 µs` | ` 13.03 µs` | ` 13.14 µs` || BigInt64Array -> (1) | ` 12.99 µs/iter` | ` 12.87 µs` | ` 13.00 µs` | ` 13.03 µs` | ` 13.14 µs` || BigUint64Array -> (1) | ` 12.92 µs/iter` | ` 12.83 µs` | ` 12.93 µs` | ` 12.97 µs` | ` 13.00 µs` || DataView -> (1) | ` 12.92 µs/iter` | ` 12.82 µs` | ` 12.95 µs` | ` 12.97 µs` | ` 12.97 µs` || Date -> (1) | ` 11.36 µs/iter` | ` 11.26 µs` | ` 11.40 µs` | ` 11.41 µs` | ` 11.42 µs` |
| • worker 100 | avg | min | p75 | p99 | max || ----------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (100) | `186.16 µs/iter` | `120.42 µs` | `198.42 µs` | `677.46 µs` | ` 1.44 ms` || bigint small -> (100) | `225.28 µs/iter` | `150.83 µs` | `244.08 µs` | `766.75 µs` | ` 1.33 ms` || bigint large -> (100) | `228.58 µs/iter` | `151.13 µs` | `247.13 µs` | `766.54 µs` | ` 1.57 ms` || boolean true -> (100) | `186.21 µs/iter` | `119.21 µs` | `198.42 µs` | `688.25 µs` | ` 1.61 ms` || boolean false -> (100) | `188.23 µs/iter` | `120.71 µs` | `200.21 µs` | `710.79 µs` | ` 1.69 ms` || undefined -> (100) | `185.35 µs/iter` | `121.92 µs` | `197.79 µs` | `672.88 µs` | ` 1.51 ms` || null -> (100) | `187.17 µs/iter` | `120.04 µs` | `198.88 µs` | `704.04 µs` | ` 1.55 ms` || string -> (100) | `192.56 µs/iter` | `121.58 µs` | `205.83 µs` | `747.04 µs` | ` 1.57 ms` || json object -> (100) | `409.65 µs/iter` | `286.46 µs` | `431.88 µs` | `971.58 µs` | ` 1.39 ms` || json array -> (100) | `538.27 µs/iter` | `394.75 µs` | `554.08 µs` | ` 1.18 ms` | ` 1.39 ms` || Uint8Array -> (100) | `329.11 µs/iter` | `207.67 µs` | `325.63 µs` | ` 1.41 ms` | ` 5.20 ms` || ArrayBuffer -> (100) | `291.22 µs/iter` | `187.96 µs` | `296.54 µs` | ` 1.12 ms` | ` 3.67 ms` || Buffer -> (100) | `323.56 µs/iter` | `203.96 µs` | `323.38 µs` | ` 1.49 ms` | ` 2.07 ms` || string huge -> (100) | `205.38 µs/iter` | `124.54 µs` | `213.13 µs` | `779.42 µs` | ` 1.69 ms` || Int32Array -> (100) | `323.10 µs/iter` | `203.96 µs` | `322.33 µs` | ` 1.42 ms` | ` 5.23 ms` || Float64Array -> (100) | `324.65 µs/iter` | `203.08 µs` | `323.54 µs` | ` 1.36 ms` | ` 2.38 ms` || BigInt64Array -> (100) | `319.81 µs/iter` | `205.42 µs` | `321.04 µs` | ` 1.56 ms` | ` 2.17 ms` || BigUint64Array -> (100) | `323.90 µs/iter` | `203.54 µs` | `322.75 µs` | ` 1.49 ms` | ` 2.21 ms` || DataView -> (100) | `317.78 µs/iter` | `199.58 µs` | `317.50 µs` | ` 1.53 ms` | ` 2.27 ms` || Date -> (100) | `227.29 µs/iter` | `149.71 µs` | `242.04 µs` | `742.83 µs` | ` 1.72 ms` |100 messages
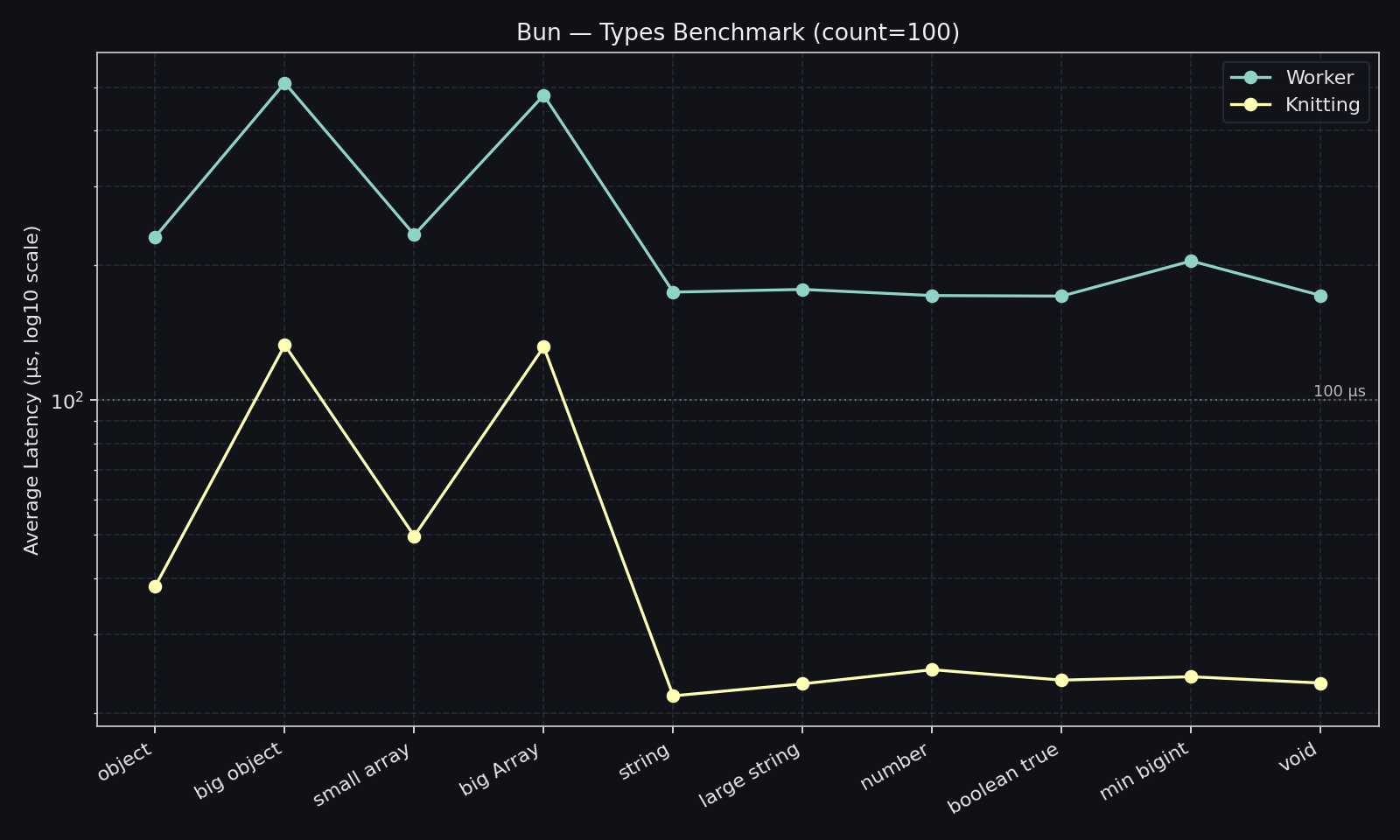
Section titled “100 messages”At 100 messages per iteration, the gap remains strong:
- Typical primitives stay around
~7-9xfaster with Knitting. - Heavier payloads still keep a clear edge at roughly
~3.7-3.9xfaster. - Batching improves throughput for both, but Knitting remains lower-overhead across payload classes.
clk: ~3.67 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • knitting 1 | avg | min | p75 | p99 | max || --------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (1) | ` 2.13 µs/iter` | `500.00 ns` | ` 2.96 µs` | ` 8.71 µs` | `362.42 µs` || bigint small -> (1) | ` 2.14 µs/iter` | ` 1.35 µs` | ` 2.49 µs` | ` 3.15 µs` | ` 3.18 µs` || bigint large -> (1) | ` 4.10 µs/iter` | ` 2.08 µs` | ` 4.13 µs` | ` 11.83 µs` | ` 1.64 ms` || boolean true -> (1) | ` 1.26 µs/iter` | `609.65 ns` | ` 1.78 µs` | ` 2.82 µs` | ` 2.86 µs` || boolean false -> (1) | ` 1.35 µs/iter` | `628.39 ns` | ` 1.85 µs` | ` 2.93 µs` | ` 2.95 µs` || undefined -> (1) | ` 1.40 µs/iter` | `621.26 ns` | ` 1.93 µs` | ` 2.69 µs` | ` 2.77 µs` || null -> (1) | ` 1.44 µs/iter` | `634.12 ns` | ` 1.97 µs` | ` 2.71 µs` | ` 2.97 µs` || string -> (1) | ` 2.75 µs/iter` | `625.00 ns` | ` 3.21 µs` | ` 8.79 µs` | `384.17 µs` || json object -> (1) | ` 4.50 µs/iter` | ` 2.33 µs` | ` 5.00 µs` | ` 16.29 µs` | ` 1.48 ms` || json array -> (1) | ` 4.79 µs/iter` | ` 4.23 µs` | ` 4.92 µs` | ` 5.31 µs` | ` 5.31 µs` || Uint8Array -> (1) | ` 4.17 µs/iter` | ` 1.58 µs` | ` 4.38 µs` | ` 12.25 µs` | ` 3.37 ms` || ArrayBuffer -> (1) | ` 4.37 µs/iter` | ` 1.38 µs` | ` 4.79 µs` | ` 12.42 µs` | ` 3.04 ms` || Buffer -> (1) | ` 3.57 µs/iter` | ` 2.61 µs` | ` 3.85 µs` | ` 4.43 µs` | ` 4.46 µs` || string huge -> (1) | ` 3.52 µs/iter` | ` 2.57 µs` | ` 3.86 µs` | ` 4.07 µs` | ` 4.25 µs` || Int32Array -> (1) | ` 3.81 µs/iter` | ` 2.85 µs` | ` 4.16 µs` | ` 4.82 µs` | ` 4.94 µs` || Float64Array -> (1) | ` 3.50 µs/iter` | ` 1.13 µs` | ` 3.75 µs` | ` 10.75 µs` | ` 1.51 ms` || BigInt64Array -> (1) | ` 4.03 µs/iter` | ` 2.80 µs` | ` 4.52 µs` | ` 4.94 µs` | ` 5.04 µs` || BigUint64Array -> (1) | ` 4.04 µs/iter` | ` 2.79 µs` | ` 4.58 µs` | ` 5.14 µs` | ` 5.19 µs` || DataView -> (1) | ` 4.02 µs/iter` | ` 2.93 µs` | ` 4.40 µs` | ` 5.01 µs` | ` 5.04 µs` || Date -> (1) | ` 2.29 µs/iter` | ` 1.25 µs` | ` 2.71 µs` | ` 3.08 µs` | ` 3.11 µs` |
| • knitting 100 | avg | min | p75 | p99 | max || ----------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (100) | ` 31.40 µs/iter` | ` 14.96 µs` | ` 41.63 µs` | ` 86.79 µs` | ` 4.11 ms` || bigint small -> (100) | ` 32.56 µs/iter` | ` 29.93 µs` | ` 34.02 µs` | ` 34.18 µs` | ` 34.25 µs` || bigint large -> (100) | `116.20 µs/iter` | ` 82.33 µs` | `114.04 µs` | `366.38 µs` | ` 1.67 ms` || boolean true -> (100) | ` 31.78 µs/iter` | ` 24.84 µs` | ` 33.50 µs` | ` 34.93 µs` | ` 35.44 µs` || boolean false -> (100) | ` 31.52 µs/iter` | ` 27.25 µs` | ` 32.22 µs` | ` 35.46 µs` | ` 36.06 µs` || undefined -> (100) | ` 32.86 µs/iter` | ` 27.91 µs` | ` 34.44 µs` | ` 35.93 µs` | ` 38.27 µs` || null -> (100) | ` 32.75 µs/iter` | ` 27.48 µs` | ` 35.88 µs` | ` 37.04 µs` | ` 37.32 µs` || string -> (100) | ` 34.33 µs/iter` | ` 29.95 µs` | ` 36.04 µs` | ` 37.41 µs` | ` 39.64 µs` || json object -> (100) | `121.78 µs/iter` | ` 89.04 µs` | `125.21 µs` | `221.00 µs` | `544.79 µs` || json array -> (100) | `146.27 µs/iter` | `114.50 µs` | `151.71 µs` | `263.79 µs` | ` 1.62 ms` || Uint8Array -> (100) | `113.40 µs/iter` | ` 53.58 µs` | `113.33 µs` | `947.38 µs` | ` 3.12 ms` || ArrayBuffer -> (100) | `108.31 µs/iter` | ` 47.63 µs` | `108.71 µs` | `924.00 µs` | ` 3.18 ms` || Buffer -> (100) | `106.11 µs/iter` | ` 45.54 µs` | `114.92 µs` | `879.42 µs` | ` 1.79 ms` || string huge -> (100) | ` 79.03 µs/iter` | ` 38.88 µs` | ` 92.92 µs` | `191.17 µs` | ` 1.68 ms` || Int32Array -> (100) | `103.97 µs/iter` | ` 49.96 µs` | ` 98.42 µs` | `949.13 µs` | ` 3.45 ms` || Float64Array -> (100) | ` 70.94 µs/iter` | ` 37.46 µs` | ` 81.75 µs` | `158.42 µs` | ` 1.69 ms` || BigInt64Array -> (100) | `106.06 µs/iter` | ` 49.83 µs` | ` 99.50 µs` | `981.92 µs` | ` 3.84 ms` || BigUint64Array -> (100) | `104.32 µs/iter` | ` 50.96 µs` | ` 99.50 µs` | `946.75 µs` | ` 4.07 ms` || DataView -> (100) | `100.39 µs/iter` | ` 51.21 µs` | ` 98.75 µs` | `933.13 µs` | ` 3.82 ms` || Date -> (100) | ` 31.76 µs/iter` | ` 26.90 µs` | ` 33.15 µs` | ` 33.81 µs` | ` 37.27 µs` |
| • worker 1 | avg | min | p75 | p99 | max || --------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (1) | ` 11.23 µs/iter` | ` 6.08 µs` | ` 11.42 µs` | ` 37.38 µs` | `397.63 µs` || bigint small -> (1) | ` 11.48 µs/iter` | ` 11.35 µs` | ` 11.52 µs` | ` 11.57 µs` | ` 11.61 µs` || bigint large -> (1) | ` 11.42 µs/iter` | ` 11.29 µs` | ` 11.47 µs` | ` 11.47 µs` | ` 11.48 µs` || boolean true -> (1) | ` 11.58 µs/iter` | ` 11.53 µs` | ` 11.60 µs` | ` 11.61 µs` | ` 11.67 µs` || boolean false -> (1) | ` 11.53 µs/iter` | ` 11.49 µs` | ` 11.54 µs` | ` 11.57 µs` | ` 11.58 µs` || undefined -> (1) | ` 11.52 µs/iter` | ` 11.47 µs` | ` 11.54 µs` | ` 11.56 µs` | ` 11.60 µs` || null -> (1) | ` 11.57 µs/iter` | ` 11.47 µs` | ` 11.60 µs` | ` 11.63 µs` | ` 11.64 µs` || string -> (1) | ` 11.62 µs/iter` | ` 11.53 µs` | ` 11.65 µs` | ` 11.68 µs` | ` 11.69 µs` || json object -> (1) | ` 15.02 µs/iter` | ` 14.88 µs` | ` 15.07 µs` | ` 15.19 µs` | ` 15.27 µs` || json array -> (1) | ` 17.80 µs/iter` | ` 17.65 µs` | ` 17.92 µs` | ` 17.95 µs` | ` 18.00 µs` || Uint8Array -> (1) | ` 12.96 µs/iter` | ` 12.84 µs` | ` 13.00 µs` | ` 13.04 µs` | ` 13.06 µs` || ArrayBuffer -> (1) | ` 12.41 µs/iter` | ` 12.31 µs` | ` 12.45 µs` | ` 12.51 µs` | ` 12.63 µs` || Buffer -> (1) | ` 12.94 µs/iter` | ` 12.86 µs` | ` 12.99 µs` | ` 13.01 µs` | ` 13.07 µs` || string huge -> (1) | ` 11.68 µs/iter` | ` 11.57 µs` | ` 11.69 µs` | ` 11.73 µs` | ` 11.76 µs` || Int32Array -> (1) | ` 12.99 µs/iter` | ` 12.85 µs` | ` 13.04 µs` | ` 13.07 µs` | ` 13.08 µs` || Float64Array -> (1) | ` 12.97 µs/iter` | ` 12.81 µs` | ` 12.98 µs` | ` 13.03 µs` | ` 13.14 µs` || BigInt64Array -> (1) | ` 12.99 µs/iter` | ` 12.87 µs` | ` 13.00 µs` | ` 13.03 µs` | ` 13.14 µs` || BigUint64Array -> (1) | ` 12.92 µs/iter` | ` 12.83 µs` | ` 12.93 µs` | ` 12.97 µs` | ` 13.00 µs` || DataView -> (1) | ` 12.92 µs/iter` | ` 12.82 µs` | ` 12.95 µs` | ` 12.97 µs` | ` 12.97 µs` || Date -> (1) | ` 11.36 µs/iter` | ` 11.26 µs` | ` 11.40 µs` | ` 11.41 µs` | ` 11.42 µs` |
| • worker 100 | avg | min | p75 | p99 | max || ----------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (100) | `186.16 µs/iter` | `120.42 µs` | `198.42 µs` | `677.46 µs` | ` 1.44 ms` || bigint small -> (100) | `225.28 µs/iter` | `150.83 µs` | `244.08 µs` | `766.75 µs` | ` 1.33 ms` || bigint large -> (100) | `228.58 µs/iter` | `151.13 µs` | `247.13 µs` | `766.54 µs` | ` 1.57 ms` || boolean true -> (100) | `186.21 µs/iter` | `119.21 µs` | `198.42 µs` | `688.25 µs` | ` 1.61 ms` || boolean false -> (100) | `188.23 µs/iter` | `120.71 µs` | `200.21 µs` | `710.79 µs` | ` 1.69 ms` || undefined -> (100) | `185.35 µs/iter` | `121.92 µs` | `197.79 µs` | `672.88 µs` | ` 1.51 ms` || null -> (100) | `187.17 µs/iter` | `120.04 µs` | `198.88 µs` | `704.04 µs` | ` 1.55 ms` || string -> (100) | `192.56 µs/iter` | `121.58 µs` | `205.83 µs` | `747.04 µs` | ` 1.57 ms` || json object -> (100) | `409.65 µs/iter` | `286.46 µs` | `431.88 µs` | `971.58 µs` | ` 1.39 ms` || json array -> (100) | `538.27 µs/iter` | `394.75 µs` | `554.08 µs` | ` 1.18 ms` | ` 1.39 ms` || Uint8Array -> (100) | `329.11 µs/iter` | `207.67 µs` | `325.63 µs` | ` 1.41 ms` | ` 5.20 ms` || ArrayBuffer -> (100) | `291.22 µs/iter` | `187.96 µs` | `296.54 µs` | ` 1.12 ms` | ` 3.67 ms` || Buffer -> (100) | `323.56 µs/iter` | `203.96 µs` | `323.38 µs` | ` 1.49 ms` | ` 2.07 ms` || string huge -> (100) | `205.38 µs/iter` | `124.54 µs` | `213.13 µs` | `779.42 µs` | ` 1.69 ms` || Int32Array -> (100) | `323.10 µs/iter` | `203.96 µs` | `322.33 µs` | ` 1.42 ms` | ` 5.23 ms` || Float64Array -> (100) | `324.65 µs/iter` | `203.08 µs` | `323.54 µs` | ` 1.36 ms` | ` 2.38 ms` || BigInt64Array -> (100) | `319.81 µs/iter` | `205.42 µs` | `321.04 µs` | ` 1.56 ms` | ` 2.17 ms` || BigUint64Array -> (100) | `323.90 µs/iter` | `203.54 µs` | `322.75 µs` | ` 1.49 ms` | ` 2.21 ms` || DataView -> (100) | `317.78 µs/iter` | `199.58 µs` | `317.50 µs` | ` 1.53 ms` | ` 2.27 ms` || Date -> (100) | `227.29 µs/iter` | `149.71 µs` | `242.04 µs` | `742.83 µs` | ` 1.72 ms` |Call growth throughput (Bun)
Section titled “Call growth throughput (Bun)”This benchmark increases payload size from 32 B up to 1,048,576 B (1 MiB) and reports
batched cost with batch=64.
Using the 1048576 B row (avg) from the batch=64 run, one-way transfer throughput is:
string:5.66 ms/iter->11.86 GB/sUint8Array:4.14 ms/iter->16.21 GB/s
Interpretation:
- Bun remains the fastest runtime in this batched 1 MiB shape for both string and binary payloads.
- The
Uint8Arraypath clears16 GB/sone-way equivalent in this run, with string close to12 GB/s.
clk: ~3.68 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • call growth batch string (ascii 32..1048576 x4, batch=64) | avg | min | p75 | p99 | max || --------- | ---------------- | ----------- | ----------- | ----------- | ----------- || 32 B | ` 25.85 µs/iter` | ` 11.46 µs` | ` 29.63 µs` | ` 80.08 µs` | ` 1.94 ms` || 128 B | ` 22.32 µs/iter` | ` 20.54 µs` | ` 22.99 µs` | ` 23.68 µs` | ` 25.10 µs` || 512 B | ` 28.31 µs/iter` | ` 25.67 µs` | ` 29.32 µs` | ` 29.67 µs` | ` 30.50 µs` || 2048 B | ` 67.00 µs/iter` | ` 28.96 µs` | ` 70.29 µs` | `247.21 µs` | ` 2.73 ms` || 8192 B | `130.66 µs/iter` | ` 71.17 µs` | `142.79 µs` | `323.83 µs` | ` 1.84 ms` || 32768 B | `208.32 µs/iter` | `123.29 µs` | `214.96 µs` | `652.54 µs` | ` 1.84 ms` || 131072 B | `592.88 µs/iter` | `418.63 µs` | `592.92 µs` | ` 1.88 ms` | ` 2.25 ms` || 524288 B | ` 2.82 ms/iter` | ` 1.77 ms` | ` 3.36 ms` | ` 6.20 ms` | ` 6.64 ms` || 1048576 B | ` 5.66 ms/iter` | ` 3.85 ms` | ` 5.85 ms` | ` 10.93 ms` | ` 10.98 ms` |
| • call growth batch uint8array (32..1048576 x4, batch=64) | avg | min | p75 | p99 | max || --------- | ---------------- | ----------- | ----------- | ----------- | ----------- || 32 B | ` 25.21 µs/iter` | ` 13.38 µs` | ` 30.13 µs` | ` 56.04 µs` | ` 1.53 ms` || 128 B | ` 23.71 µs/iter` | ` 20.35 µs` | ` 25.02 µs` | ` 25.26 µs` | ` 26.54 µs` || 512 B | ` 22.87 µs/iter` | ` 20.79 µs` | ` 23.68 µs` | ` 23.82 µs` | ` 24.01 µs` || 2048 B | ` 67.13 µs/iter` | ` 33.50 µs` | ` 70.92 µs` | `132.92 µs` | ` 7.98 ms` || 8192 B | `116.93 µs/iter` | ` 62.04 µs` | `114.25 µs` | `221.04 µs` | ` 3.13 ms` || 32768 B | `193.72 µs/iter` | `131.08 µs` | `173.92 µs` | ` 1.01 ms` | ` 2.90 ms` || 131072 B | `571.40 µs/iter` | `348.29 µs` | `523.71 µs` | ` 2.01 ms` | ` 2.32 ms` || 524288 B | ` 2.37 ms/iter` | ` 1.59 ms` | ` 3.00 ms` | ` 5.19 ms` | ` 6.12 ms` || 1048576 B | ` 4.14 ms/iter` | ` 3.08 ms` | ` 4.64 ms` | ` 6.30 ms` | ` 9.65 ms` |Efficiency under heavy tasks (Bun)
Section titled “Efficiency under heavy tasks (Bun)”This stress test computes prime numbers over a large range, then serializes and parses large JSON payloads:
const N = 10_000_000; // search range: [1..N]const CHUNK_SIZE = 250_000;Even under this heavier workload, parallel workers scale well:
main + 1 extra thread:~1.8xfaster than main only.main + 2 extra threads:~2.5xfaster than main only.main + 3 extra threads:~3.3xfaster than main only.main + 4 extra threads:~3.8xfaster than main only.
clk: ~3.69 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • knitting: primes up to 10,000,000 (chunk=250,000) | avg | min | p75 | p99 | max || ----------------------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || main | `572.57 ms/iter` | `569.05 ms` | `573.73 ms` | `576.83 ms` | `577.70 ms` || main + 1 extra threads → full range | `304.05 ms/iter` | `299.51 ms` | `305.94 ms` | `310.39 ms` | `310.63 ms` || main + 2 extra threads → full range | `224.68 ms/iter` | `220.21 ms` | `228.08 ms` | `230.10 ms` | `230.84 ms` || main + 3 extra threads → full range | `179.33 ms/iter` | `174.37 ms` | `181.15 ms` | `181.78 ms` | `182.35 ms` || main + 4 extra threads → full range | `157.48 ms/iter` | `153.46 ms` | `159.02 ms` | `159.85 ms` | `160.47 ms` |All types in Knitting
Section titled “All types in Knitting”This benchmark covers primitive, structured, collection, typed-array, error/date/symbol, promise-arg, and static-vs-dynamic allocator paths.
Results are reported for count 1 and count 100 to show both per-call latency and batched throughput.
Quick takeaways:
- In count
100, primitive-style payloads are usually in the~16-25 µsrange, while heavier structured/collection payloads are often~60-270 µswith occasional larger spikes. - The static payload path is usually around
~1.3x-3.1xfaster than dynamic allocator paths (for example: string~1.8x, json~2.1x,Uint8Array~1.3x, symbol~3.1xat count100).
Payload sizes (approximate):
| Payload | Size |
|---|---|
jsonObj | 206 B |
jsonArr | 217 B |
mapPayload | 284 B |
Uint8Array | 1024 B |
Int32Array | 1024 B |
Float64Array | 1024 B |
BigInt64Array | 1024 B |
BigUint64Array | 1024 B |
DataView | 1024 B |
smallU8 | 480 B |
largeU8 | 481 B |
payload sizes (approx bytes): jsonObj: 206 bytes jsonArr: 217 bytes stringHuge: 1024 bytes Uint8Array: 1024 bytes Int32Array: 1024 bytes Float64Array: 1024 bytes BigInt64Array: 1024 bytes BigUint64Array: 1024 bytes DataView: 1024 bytes
clk: ~3.69 GHzcpu: Apple M3 Ultraruntime: bun 1.3.6 (arm64-darwin)
| • knitting-types 1 | avg | min | p75 | p99 | max || --------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (1) | ` 1.88 µs/iter` | `459.00 ns` | ` 2.83 µs` | ` 8.17 µs` | `433.21 µs` || bigint small -> (1) | ` 2.19 µs/iter` | ` 1.50 µs` | ` 2.48 µs` | ` 3.01 µs` | ` 3.07 µs` || bigint large -> (1) | ` 4.01 µs/iter` | ` 2.04 µs` | ` 4.04 µs` | ` 12.50 µs` | ` 1.73 ms` || boolean true -> (1) | ` 1.33 µs/iter` | `707.16 ns` | ` 1.68 µs` | ` 2.48 µs` | ` 2.74 µs` || boolean false -> (1) | ` 1.09 µs/iter` | `710.70 ns` | ` 1.35 µs` | ` 2.14 µs` | ` 2.47 µs` || undefined -> (1) | ` 1.16 µs/iter` | `648.72 ns` | ` 1.51 µs` | ` 2.57 µs` | ` 2.89 µs` || null -> (1) | ` 1.03 µs/iter` | `649.21 ns` | ` 1.30 µs` | ` 2.70 µs` | ` 2.92 µs` || string -> (1) | ` 2.39 µs/iter` | `625.00 ns` | ` 2.92 µs` | ` 7.88 µs` | `448.88 µs` || json object -> (1) | ` 3.59 µs/iter` | ` 3.00 µs` | ` 3.82 µs` | ` 4.37 µs` | ` 4.37 µs` || json array -> (1) | ` 4.61 µs/iter` | ` 4.15 µs` | ` 4.76 µs` | ` 5.04 µs` | ` 5.09 µs` || Uint8Array -> (1) | ` 4.34 µs/iter` | ` 1.54 µs` | ` 4.67 µs` | ` 14.04 µs` | ` 3.75 ms` || ArrayBuffer -> (1) | ` 3.98 µs/iter` | ` 1.33 µs` | ` 4.42 µs` | ` 11.83 µs` | ` 3.49 ms` || Buffer -> (1) | ` 3.15 µs/iter` | ` 2.44 µs` | ` 3.46 µs` | ` 3.79 µs` | ` 3.84 µs` || string huge -> (1) | ` 3.51 µs/iter` | ` 1.29 µs` | ` 3.79 µs` | ` 11.96 µs` | ` 1.59 ms` || Int32Array -> (1) | ` 3.55 µs/iter` | ` 2.61 µs` | ` 3.92 µs` | ` 4.21 µs` | ` 4.25 µs` || Float64Array -> (1) | ` 3.00 µs/iter` | ` 1.08 µs` | ` 3.38 µs` | ` 8.79 µs` | ` 1.68 ms` || BigInt64Array -> (1) | ` 3.48 µs/iter` | ` 2.54 µs` | ` 3.86 µs` | ` 4.45 µs` | ` 4.65 µs` || BigUint64Array -> (1) | ` 3.57 µs/iter` | ` 2.58 µs` | ` 4.05 µs` | ` 4.84 µs` | ` 4.90 µs` || DataView -> (1) | ` 3.24 µs/iter` | ` 2.50 µs` | ` 3.50 µs` | ` 4.65 µs` | ` 5.04 µs` || Date -> (1) | ` 1.68 µs/iter` | `541.00 ns` | ` 1.96 µs` | ` 5.21 µs` | `466.54 µs` || Symbol.for -> (1) | ` 2.41 µs/iter` | ` 1.76 µs` | ` 2.64 µs` | ` 3.04 µs` | ` 3.04 µs` |
| • knitting-types 100 | avg | min | p75 | p99 | max || ----------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || number -> (100) | ` 32.00 µs/iter` | ` 13.96 µs` | ` 27.54 µs` | `215.88 µs` | ` 3.23 ms` || bigint small -> (100) | ` 30.26 µs/iter` | ` 27.43 µs` | ` 31.73 µs` | ` 32.18 µs` | ` 35.93 µs` || bigint large -> (100) | `122.70 µs/iter` | ` 84.33 µs` | `120.96 µs` | `425.79 µs` | ` 1.91 ms` || boolean true -> (100) | ` 27.23 µs/iter` | ` 24.14 µs` | ` 27.49 µs` | ` 29.92 µs` | ` 34.21 µs` || boolean false -> (100) | ` 28.04 µs/iter` | ` 23.23 µs` | ` 29.87 µs` | ` 32.86 µs` | ` 36.96 µs` || undefined -> (100) | ` 28.24 µs/iter` | ` 22.49 µs` | ` 29.58 µs` | ` 30.68 µs` | ` 32.45 µs` || null -> (100) | ` 25.01 µs/iter` | ` 22.17 µs` | ` 26.19 µs` | ` 27.17 µs` | ` 27.45 µs` || string -> (100) | ` 28.18 µs/iter` | ` 23.32 µs` | ` 30.81 µs` | ` 33.08 µs` | ` 41.07 µs` || json object -> (100) | `122.98 µs/iter` | ` 93.67 µs` | `125.88 µs` | `223.46 µs` | ` 1.62 ms` || json array -> (100) | `149.52 µs/iter` | `113.92 µs` | `154.54 µs` | `279.08 µs` | ` 1.66 ms` || Uint8Array -> (100) | `112.02 µs/iter` | ` 54.00 µs` | `112.13 µs` | `928.79 µs` | ` 3.12 ms` || ArrayBuffer -> (100) | `115.93 µs/iter` | ` 61.33 µs` | `113.54 µs` | `922.46 µs` | ` 3.59 ms` || Buffer -> (100) | `104.68 µs/iter` | ` 44.46 µs` | `115.63 µs` | `747.96 µs` | ` 2.11 ms` || string huge -> (100) | ` 93.47 µs/iter` | ` 46.04 µs` | `110.38 µs` | `207.17 µs` | ` 1.73 ms` || Int32Array -> (100) | `101.19 µs/iter` | ` 49.92 µs` | ` 98.04 µs` | `900.71 µs` | ` 3.78 ms` || Float64Array -> (100) | ` 71.52 µs/iter` | ` 37.50 µs` | ` 82.33 µs` | `167.50 µs` | ` 1.58 ms` || BigInt64Array -> (100) | `103.28 µs/iter` | ` 50.00 µs` | ` 98.63 µs` | `920.00 µs` | ` 3.84 ms` || BigUint64Array -> (100) | `101.80 µs/iter` | ` 50.13 µs` | ` 98.13 µs` | `908.42 µs` | ` 4.21 ms` || DataView -> (100) | `102.14 µs/iter` | ` 50.29 µs` | ` 98.92 µs` | `895.21 µs` | ` 3.87 ms` || Date -> (100) | ` 31.00 µs/iter` | ` 27.10 µs` | ` 32.35 µs` | ` 34.37 µs` | ` 38.53 µs` || Symbol.for -> (100) | ` 37.43 µs/iter` | ` 21.46 µs` | ` 47.08 µs` | ` 83.50 µs` | ` 1.56 ms` |
| • knitting-promise-args 1 | avg | min | p75 | p99 | max || --------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || promise number -> (1) | ` 2.44 µs/iter` | ` 1.76 µs` | ` 2.78 µs` | ` 3.16 µs` | ` 3.20 µs` || promise object -> (1) | ` 3.13 µs/iter` | ` 2.35 µs` | ` 3.34 µs` | ` 3.74 µs` | ` 3.79 µs` |
| • knitting-promise-args 100 | avg | min | p75 | p99 | max || ----------------------- | ---------------- | ----------- | ----------- | ----------- | ----------- || promise number -> (100) | ` 43.54 µs/iter` | ` 39.69 µs` | ` 45.25 µs` | ` 47.23 µs` | ` 48.48 µs` || promise object -> (100) | ` 61.77 µs/iter` | ` 38.13 µs` | ` 68.83 µs` | `122.88 µs` | ` 1.49 ms` |